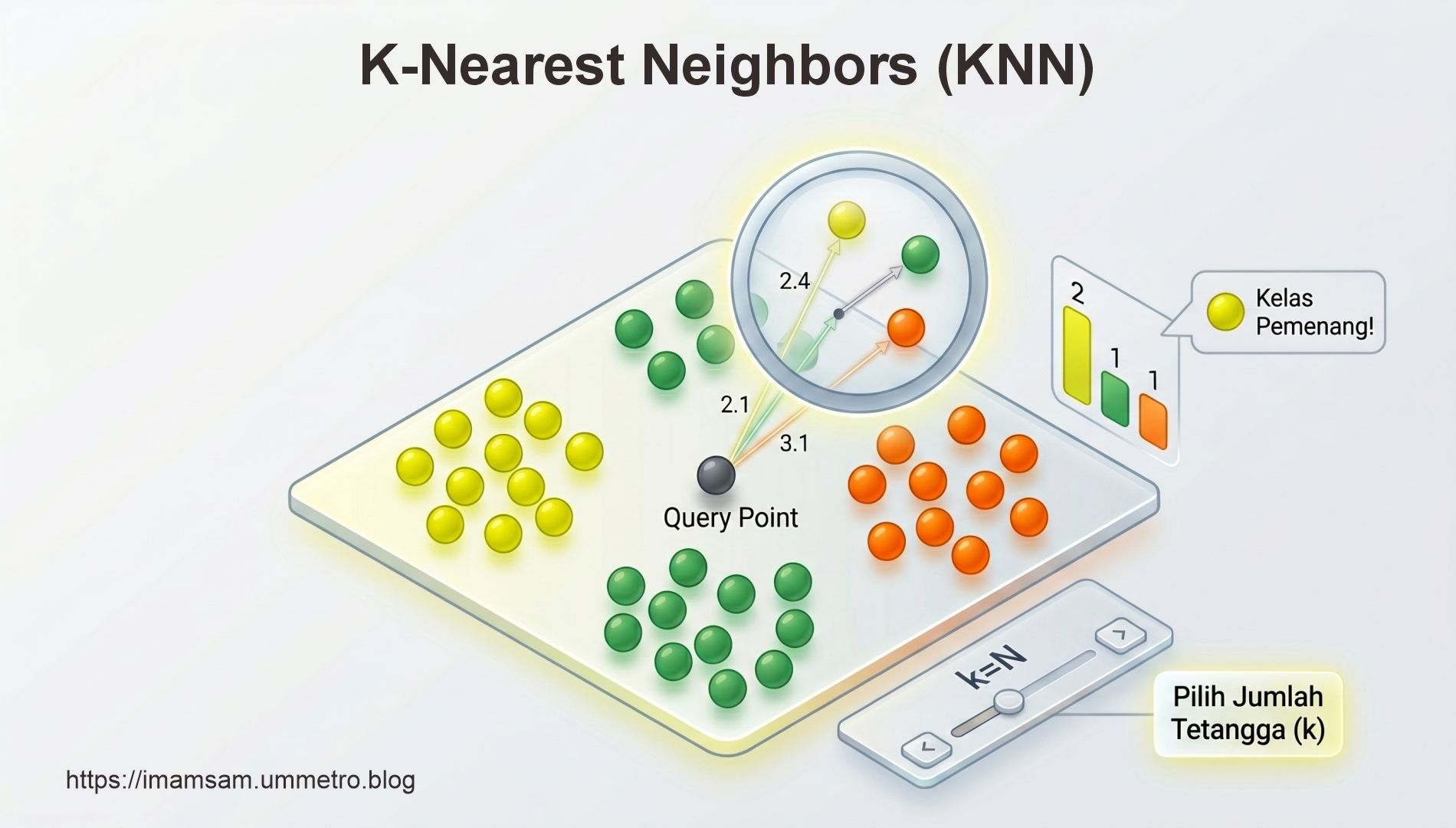
Algoritma K-Nearest Neighbors (KNN) adalah metode supervised learning yang digunakan untuk klasifikasi dan regresi, berbasis pada prinsip kedekatan (similarity-based learning). Intinya: data baru diklasifikasikan berdasarkan “tetangga terdekatnya” dalam ruang fitur.
K-Nearest Neighbors (KNN) adalah salah satu algoritma yang cukup sederhana tapi powerful dalam dunia machine learning. Algoritma ini termasuk dalam kategori lazy learning, artinya dia tidak benar-benar “belajar” dengan membangun model saat proses training. Sebaliknya, KNN hanya menyimpan seluruh data training apa adanya, lalu baru melakukan perhitungan ketika diminta membuat prediksi. Jadi, bisa dibilang kerja utamanya justru terjadi saat inference, bukan saat training. Prinsip dasar dari KNN juga cukup intuitif: data yang mirip biasanya punya label yang sama. Karena itu, ketika ada data baru, KNN akan melihat “tetangga terdekatnya” di data training, lalu menentukan label berdasarkan mayoritas dari tetangga tersebut.
Kalau kita bahas cara kerjanya, KNN sebenarnya punya alur yang cukup jelas dan mudah diikuti. Pertama, kita tentukan dulu nilai K, yaitu jumlah tetangga terdekat yang akan dipertimbangkan. Setelah itu, algoritma akan menghitung jarak antara data baru dengan seluruh data training yang ada. Hasil perhitungan jarak ini kemudian diurutkan dari yang paling dekat, karena yang paling relevan tentu adalah data dengan kemiripan tertinggi. Dari situ, diambil K data terdekat sebagai “tetangga”. Nah, tahap terakhir adalah menentukan output: kalau kasusnya klasifikasi, maka digunakan voting mayoritas dari tetangga tersebut, sedangkan untuk regresi, biasanya diambil nilai rata-rata dari K tetangga tadi.
Secara berurutan, KNN bekerja sebagai berikut:
- Tentukan nilai K (jumlah tetangga)
- Hitung jarak antara data baru dengan seluruh data training
- Urutkan berdasarkan jarak terdekat
- Ambil K data terdekat
- Tentukan output:
- Klasifikasi → voting mayoritas
- Regresi → rata-rata nilai
Fungsi Jarak (Distance Metrics)
Salah satu hal paling penting dalam KNN adalah pemilihan distance metric, karena di sinilah algoritma menentukan mana data yang “dekat” dan mana yang “jauh”.
Metrik yang paling umum dipakai adalah Euclidean Distance, yang cocok untuk data numerik kontinu karena menghitung jarak lurus antar titik seperti di ruang geometris. Euclidean Distance dapat dihitung dengan rumus persamaan sebagai berikut.
Selain itu ada Manhattan Distance, yang menghitung jarak seperti berjalan di grid (kanan-kiri, atas-bawah), dan biasanya lebih tahan terhadap outlier dibanding Euclidean. Manhattan Distance dapat dihitung dengan rumus persamaan sebagai berikut.
Jika butuh fleksibilitas, ada juga Minkowski Distance yang bisa dianggap sebagai generalisasi dari keduanya—tinggal atur nilai parameter p, maka kita bisa mendapatkan Euclidean (p=2) atau Manhattan (p=1). Minkowski Distance dapat dihitung dengan rumus sebagai berikut.
Keterangan:
- Merupakan generalisasi dari berbagai distance metric.
- Parameter p menentukan jenis jarak:
- p=1 → menjadi Manhattan Distance
- p=2 → menjadi Euclidean Distance
- p→∞ → menjadi Chebyshev Distance
- Digunakan ketika ingin fleksibilitas dalam menentukan cara mengukur jarak.
Sementara itu, untuk data dengan dimensi tinggi seperti teks, Cosine Similarity sering jadi pilihan karena yang diukur bukan jarak absolut, melainkan sudut antar vektor, sehingga lebih fokus pada arah atau pola daripada besar nilainya.